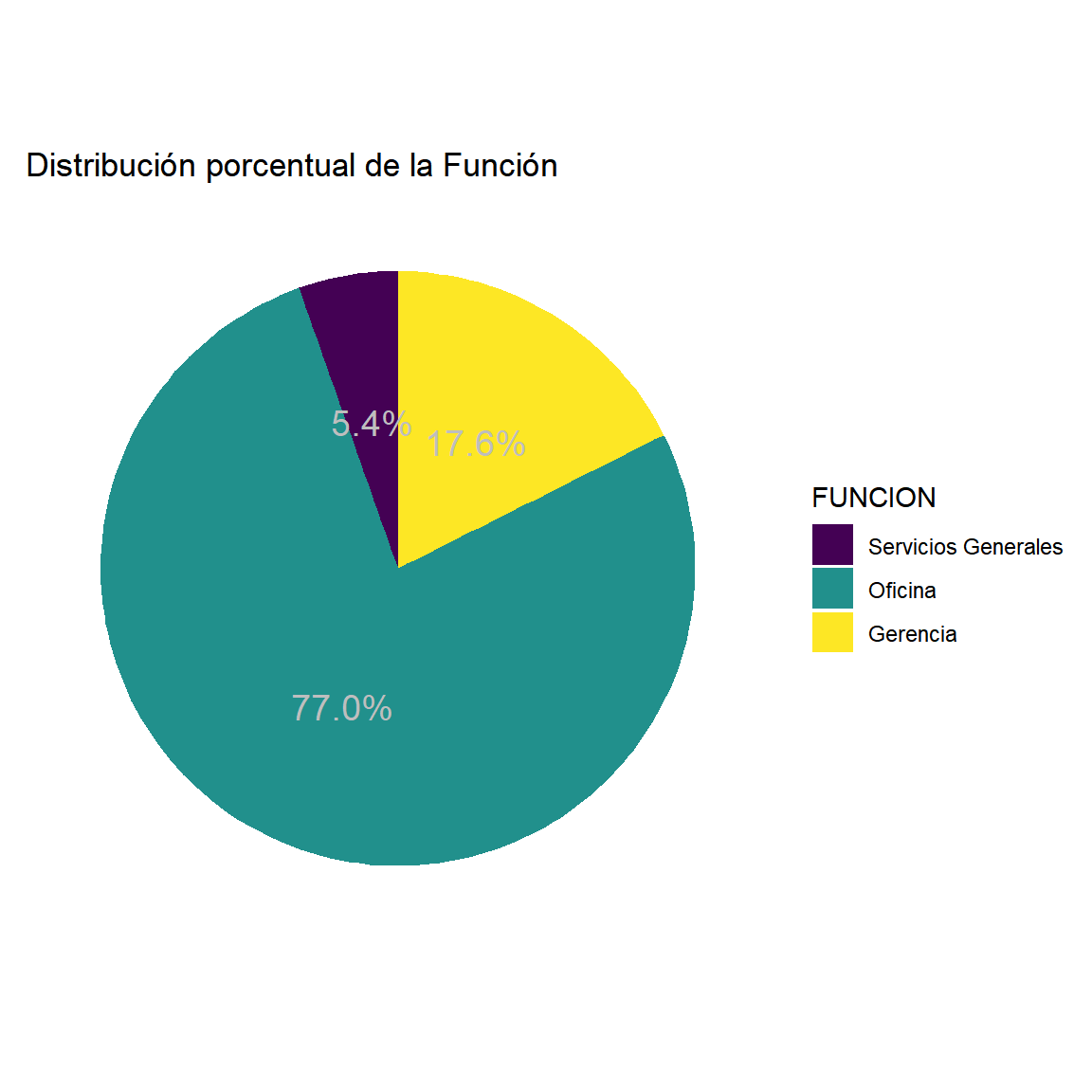Rows: 500
Columns: 10
$ SEXO <chr> "Masculino", "Masculino", "Femenino", "Femenino", "Masculi…
$ EDAD <dbl> 49, 43, 71, 54, 46, 42, 45, 35, 55, 55, 51, 35, 40, 52, 38…
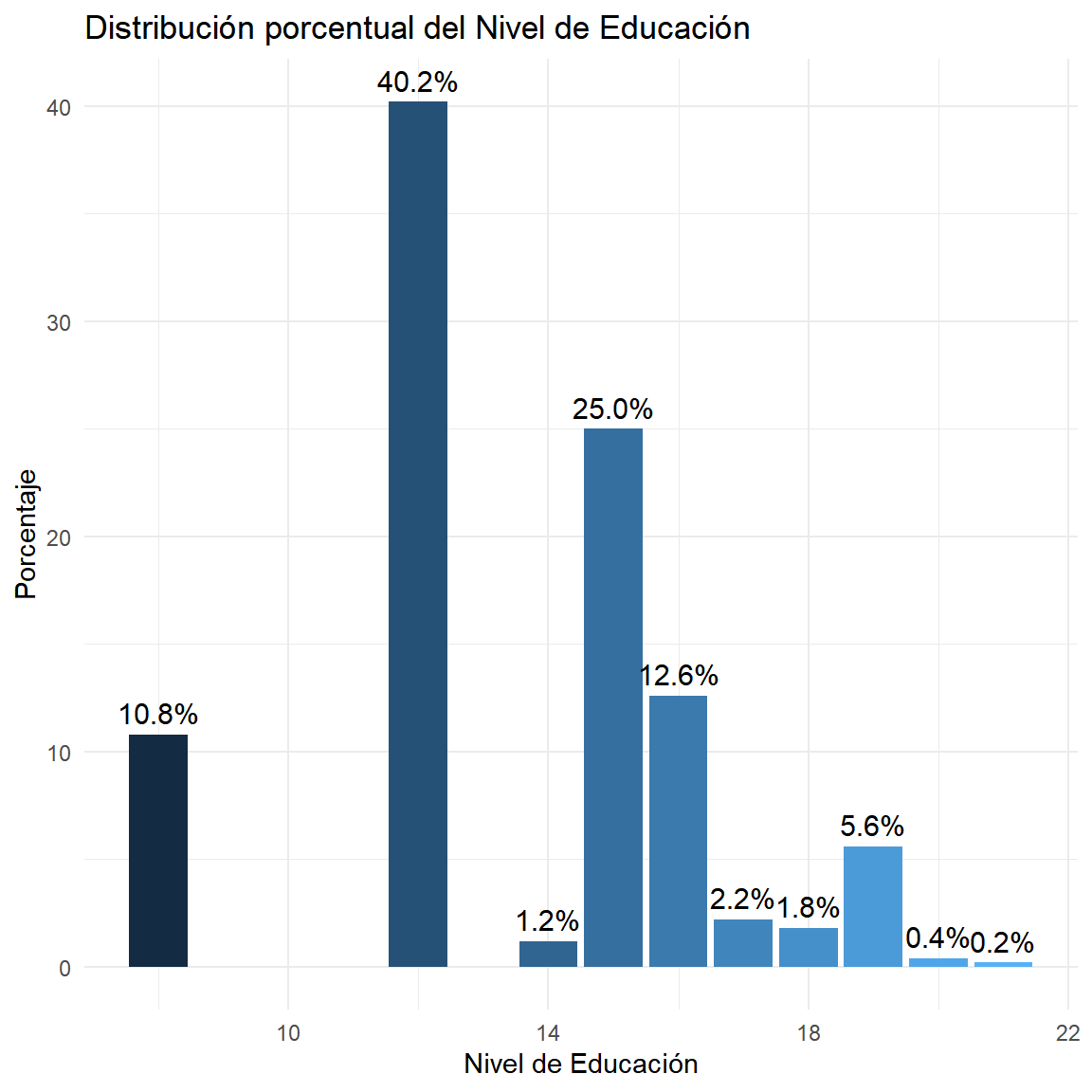
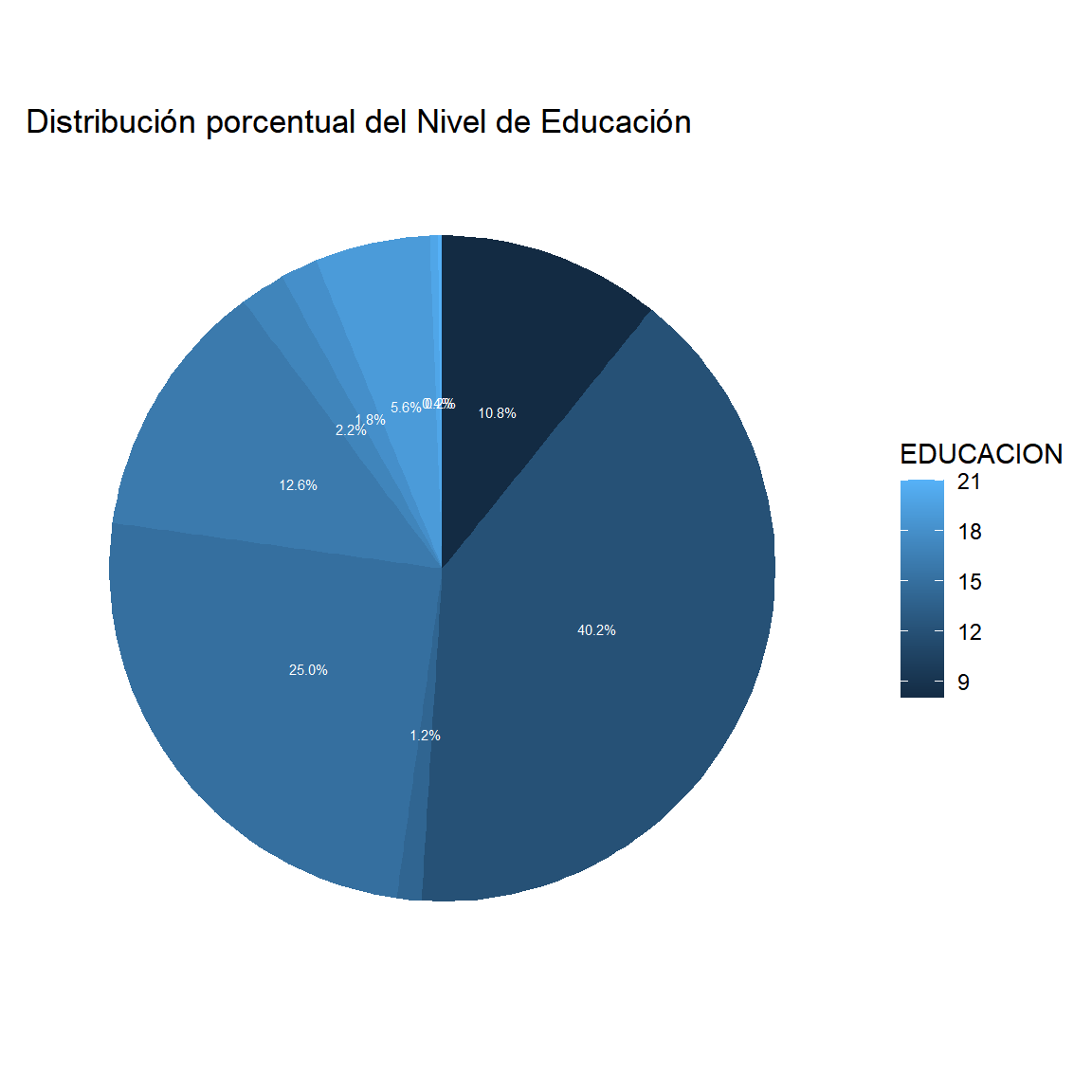
$ EDUCACION <dbl> 15, 16, 12, 8, 15, 15, 15, 12, 15, 12, 16, 8, 15, 15, 12, …
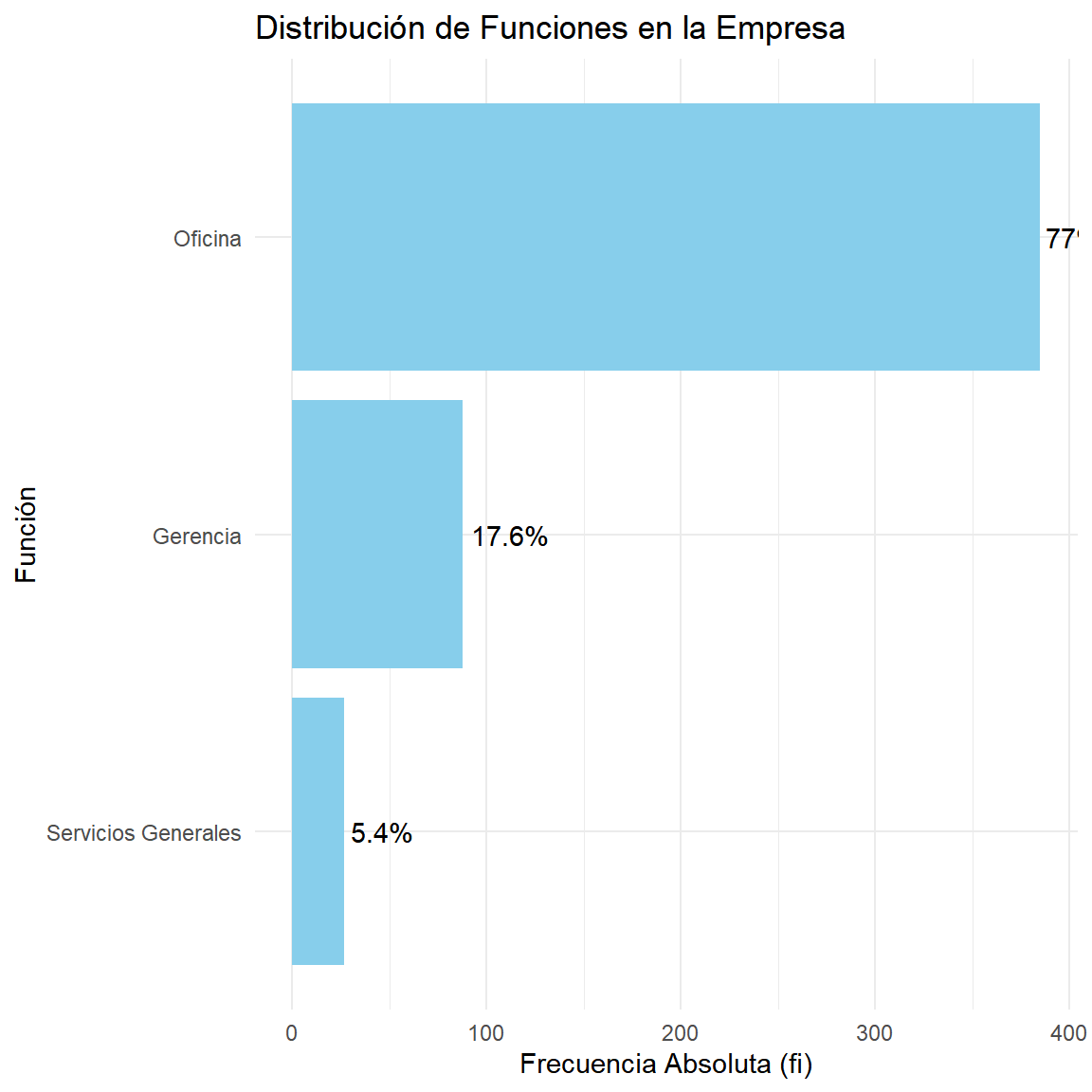
$ FUNCION <ord> Gerencia, Oficina, Oficina, Oficina, Oficina, Oficina, Ofi…
$ SALARIO <dbl> 57000, 40200, 21450, 21900, 45000, 32100, 36000, 21900, 27…
$ SERVICIO <dbl> 8.166667, 8.166667, 8.166667, 8.166667, 8.166667, 8.166667…
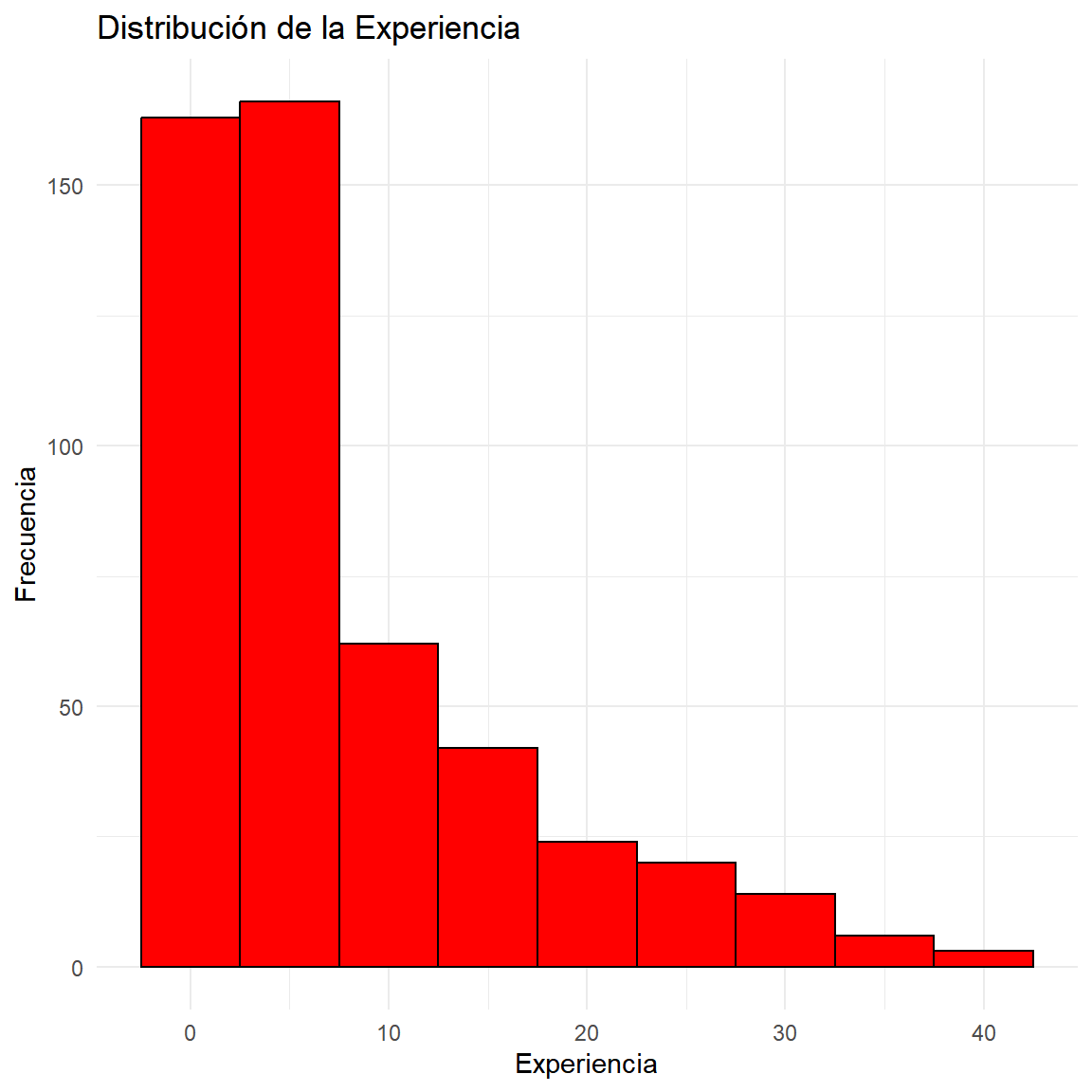
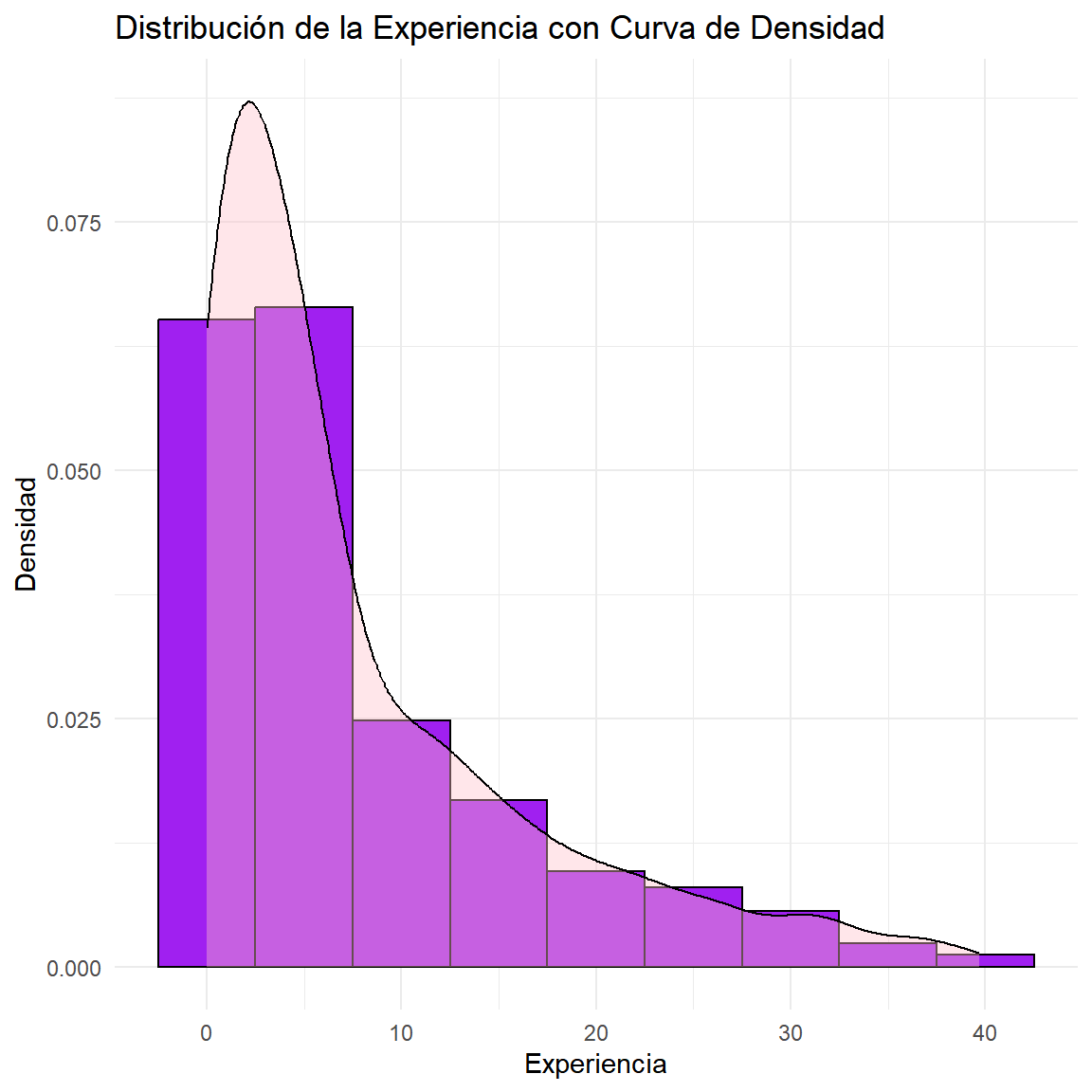
$ EXPERIENCIA <dbl> 12.000000, 3.000000, 31.750000, 15.833333, 11.500000, 5.58…
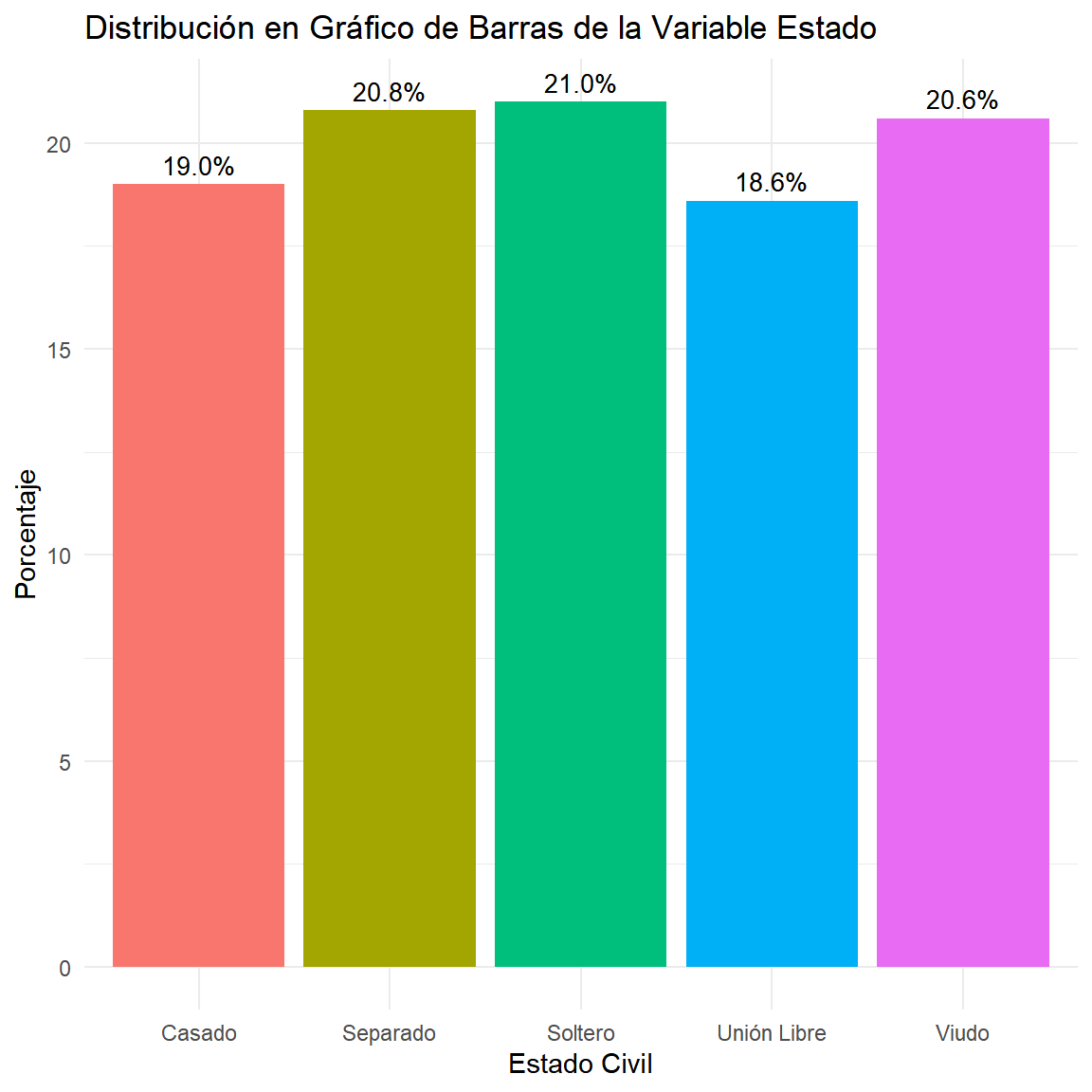
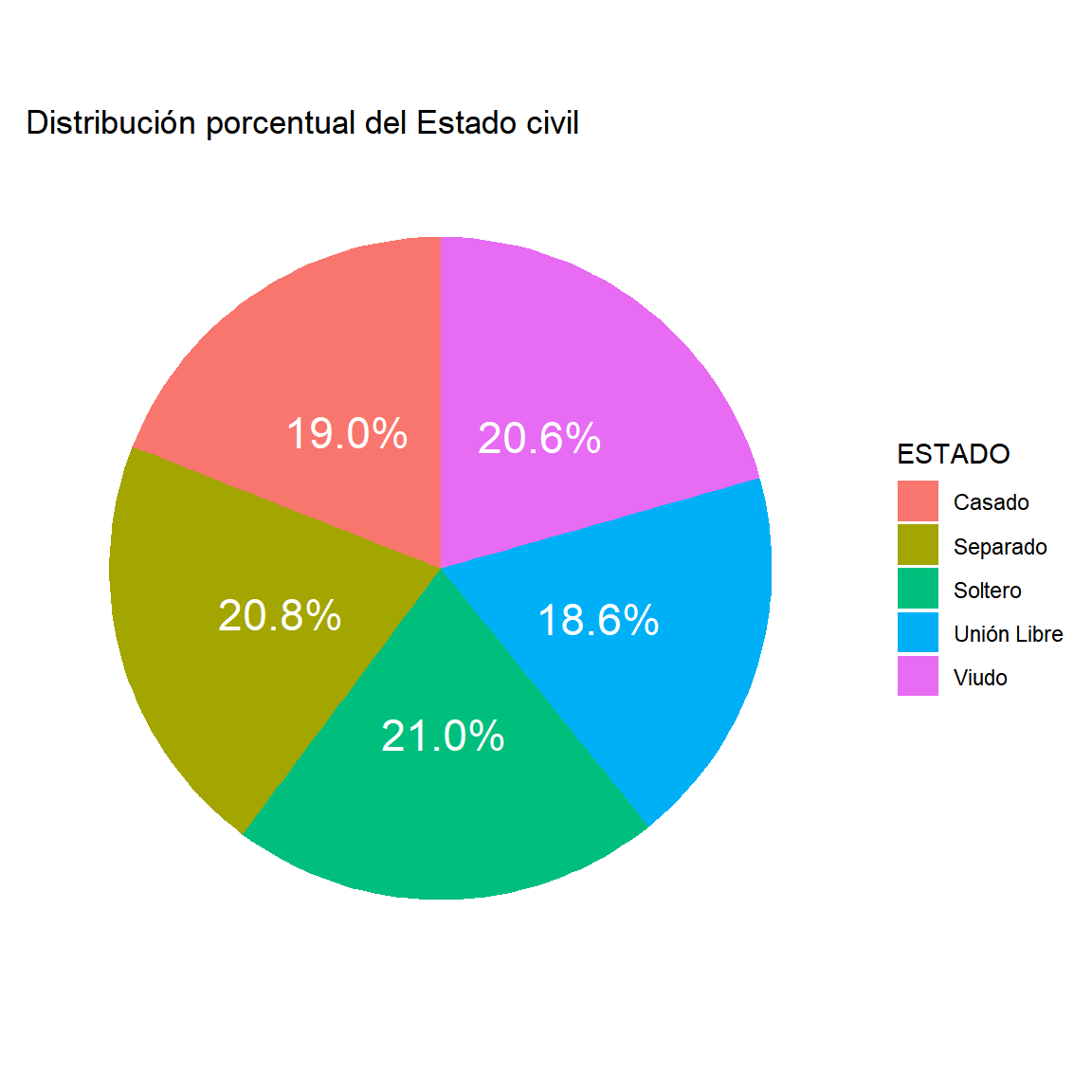
$ ESTADO <chr> "Unión Libre", "Casado", "Unión Libre", "Casado", "Soltero…
$ HIJOS <dbl> 0, 3, 0, 3, 4, 0, 1, 1, 1, 0, 1, 2, 4, 4, 3, 2, 2, 0, 4, 4…
$ ESTRATO <ord> Alto, Medio, Medio, Medio, Medio, Bajo, Bajo, Medio, Medio…